Project detail · technical deep-dive
Truth Scout — TensorFlow.js Overperformance Detector
Trained a neural network in Node to predict UCL 21/22 goals from FIFA 22 attributes, then shipped the results as a full-stack dashboard. End-to-end ML in JavaScript: data pipeline, MLP regression, Express API, React UI.
Role
Solo / ML + full-stack engineering
Timeline
2026
Tech
Node 22+, TensorFlow.js, SQLite, Express, React 18, Vite 6
7 page views
Product showcase
Flows & screens
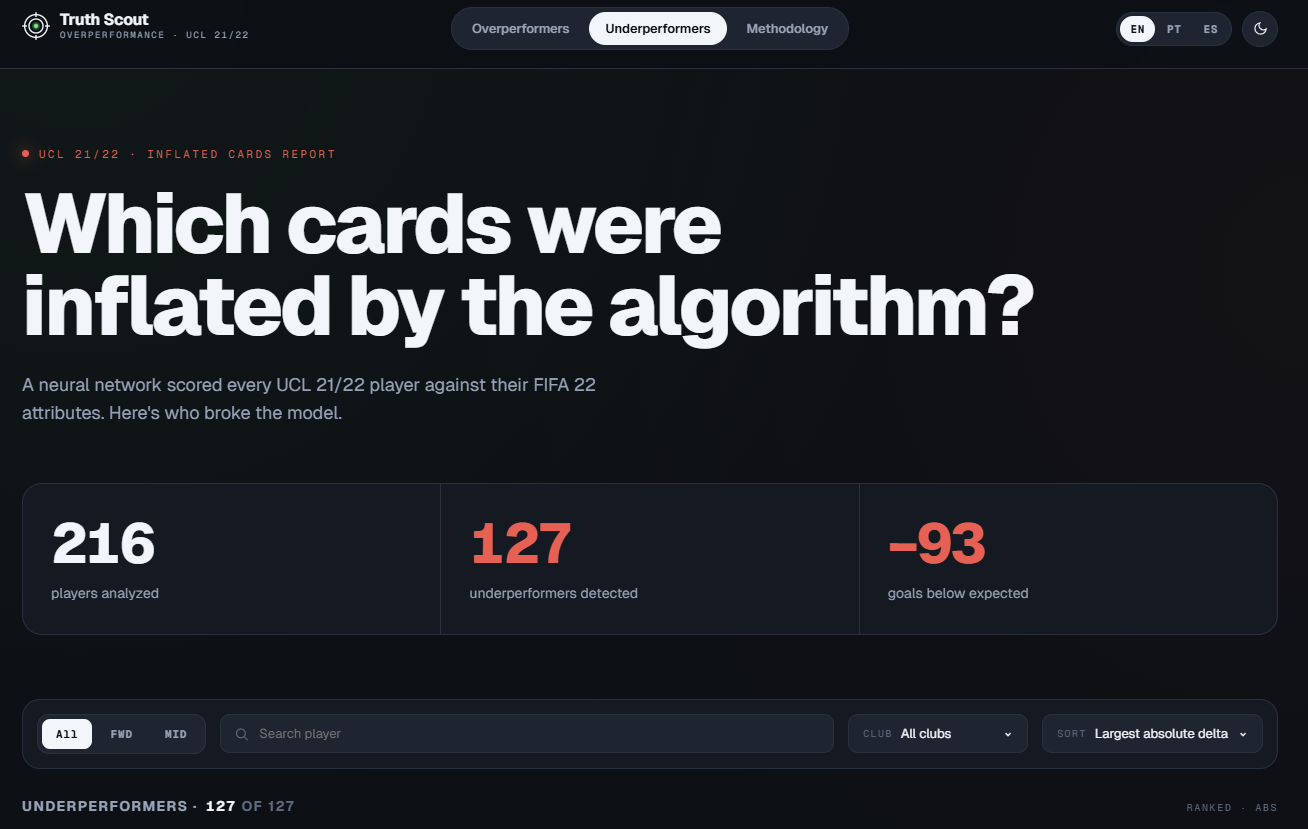
Dashboard surface: ranking of players whose UCL 21/22 goals outpaced what the model predicted from their FIFA 22 attributes.
Shipped
Status
ML + full-stack
Focus
0.18 g/match
Val. MAE
Technical implementation
Data pipeline
Five-stage ingestion written as idempotent Node scripts. xlsx → SQLite for 19k FIFA 22 players, eight CSVs merged into a unified UCL 21/22 table, fuzzy matching across both datasets, feature engineering, training, prediction — runnable end-to-end with one npm command.
ML model
Shallow MLP regressor (33 → 32 → 16 → 1) trained in TensorFlow.js. Target is goals-per-match as a rate — the model learns a continuous distribution and predicted values are scaled by each player's real match count to reconstruct tournament-level expected goals.
Position filter insight
Training on all 562 matched players flattened predictions toward zero because the MSE loss was dominated by non-scorers. Restricting the training cohort to offensive positions (FWD + attacking mids) pushed Benzema's expected from 4.4 to 9.2 — the predictions only became believable once the input distribution was honest about who scores.
Full-stack integration
SQLite predictions exposed through a thin Express API; React front end consumes three endpoints (over / under / stats) and filters client-side. Vite dev proxy plus concurrently orchestrate frontend and API in a single npm run.
Overview
Truth Scout is an end-to-end machine-learning project I built to answer one question: which footballers massively overperformed — or underperformed — what their FIFA 22 attributes said they should do in the UCL 21/22? A neural network trained on real data learns the FIFA-to-UCL mapping, and the gap between prediction and reality becomes the product.
The whole thing is written in JavaScript end-to-end — no Python sidecar, no model-server dance, no serialization between languages. TensorFlow.js trains the regression in Node during the pipeline, SQLite stores the predictions, Express serves them, and a hand-built React dashboard lets users click through the results across three languages.
The ML core
Target engineering — rate, not total
Two players with 5 goals aren't comparable if one played 3 matches and the other 13. The model learns a goals-per-match rate; the UI multiplies that rate back by each player's real match count to reconstruct tournament totals.
// target = goals / matches_played (a continuous rate in [0, ~1.5])
const targetVal = (row) => row.goals / row.matches_played;Feature vector — 33 FIFA attributes, z-score normalized
Composite ratings, attacking detail, skill, movement, power, mentality, age. Normalization constants are computed on the training set only and reapplied identically at inference to avoid data leakage.
const FEATURE_COLS = [
"overall", "potential", "age",
"pace", "shooting", "passing", "dribbling", "defending", "physic",
"attacking_finishing", "attacking_heading_accuracy", "attacking_volleys",
"attacking_short_passing", "attacking_crossing",
"skill_dribbling", "skill_curve", "skill_fk_accuracy",
"skill_long_passing", "skill_ball_control",
"movement_acceleration", "movement_sprint_speed", "movement_agility",
"movement_reactions", "movement_balance",
"power_shot_power", "power_stamina", "power_strength", "power_long_shots",
"mentality_aggression", "mentality_positioning", "mentality_vision",
"mentality_penalties", "mentality_composure",
];
const means = {}, stds = {};
for (const col of FEATURE_COLS) {
const vals = clean.map((r) => r[col]);
const m = vals.reduce((a, b) => a + b, 0) / vals.length;
const v = vals.reduce((a, b) => a + (b - m) ** 2, 0) / vals.length;
means[col] = m;
stds[col] = Math.sqrt(v) || 1; // guards against constant columns
}
const featureVec = (row) =>
FEATURE_COLS.map((c) => (row[c] - means[c]) / stds[c]);Model — shallow MLP in TensorFlow.js
1,633 parameters total. With only 216 training rows, anything deeper memorizes within 30 epochs regardless of regularization. L2 on the dense kernels + dropout 0.2 between layers keeps the generalization gap tight.
import * as tf from "@tensorflow/tfjs";
const model = tf.sequential({
layers: [
tf.layers.dense({
inputShape: [FEATURE_COLS.length],
units: 32,
activation: "relu",
kernelRegularizer: tf.regularizers.l2({ l2: 0.01 }),
}),
tf.layers.dropout({ rate: 0.2 }),
tf.layers.dense({
units: 16,
activation: "relu",
kernelRegularizer: tf.regularizers.l2({ l2: 0.01 }),
}),
tf.layers.dropout({ rate: 0.2 }),
tf.layers.dense({ units: 1, activation: "linear" }),
],
});
model.compile({
optimizer: tf.train.adam(0.003),
loss: "meanSquaredError",
metrics: ["mae"],
});Training loop with per-epoch monitoring
Deterministic shuffle → 80/20 train/val split → 200 epochs with early telemetry to catch divergence. Validation MAE stabilizes around 0.18 goals/match by epoch 40 and stays there.
await model.fit(xTrain, yTrain, {
epochs: 200,
batchSize: 32,
validationData: [xVal, yVal],
shuffle: true,
verbose: 0,
callbacks: {
onEpochEnd: (epoch, logs) => {
if (epoch % 20 === 0) {
console.log(
`epoch ${epoch}: loss=${logs.loss.toFixed(4)} ` +
`val_mae=${logs.val_mae.toFixed(4)}`
);
}
},
},
});The position-filter insight
The single most impactful decision in the pipeline — and it wasn't a hyperparameter. The first training run included all 562 matched players: defenders, goalkeepers, everyone. The MSE loss dragged predictions toward the mean of a defender-heavy cohort, and Benzema came out with an expected 4.4 goals. Restricting the training SQL to offensive positions pushed it to 9.2 without touching a single line of model code.
const ATTACKING_POSITIONS = [
"ST", "CF", "LS", "RS", "LF", "RF", // strikers
"LW", "RW", // wingers
"CAM", "LAM", "RAM", // attacking mids
"LM", "RM", // wide mids that arrive in the box
];
const joinSql = `
SELECT m.ucl_id, m.sofifa_id, u.matches_played, u.goals,
${FEATURE_COLS.map((c) => `f.${c}`).join(", ")}
FROM player_matches m
JOIN ucl_players u ON u.id = m.ucl_id
JOIN fifa22_players f ON f.sofifa_id = m.sofifa_id
WHERE u.matches_played >= 2
AND f.primary_position IN (${ATTACKING_POSITIONS.map((p) => `'${p}'`).join(", ")})
`;Prediction → product
Model output is a per-match rate, clamped at zero (can't score negative goals). Multiplied by the player's real match count, it becomes the "expected goals in tournament" number shown on each card, and the difference against real goals becomes the dashboard's story.
const predArr = (await model.predict(xAll).array()).map((a) => a[0]);
for (let i = 0; i < allRows.length; i++) {
const row = allRows[i];
const perGamePred = Math.max(0, predArr[i]);
const expected = perGamePred * row.matches_played;
const delta = row.goals - expected;
const deltaPct = expected > 0.01 ? (delta / expected) * 100 : 0;
// → persisted into SQLite, served via Express, rendered in React
}Results summary
| Validation MAE | 0.18 goals/match (~1 goal over a 6-match group stage) |
| Dataset | 216 offensive players (173 train / 43 val) |
| Training time | ~4 seconds in Node |
| Parameters | 1,633 |
| Benzema delta | +5.8 goals (expected 9.2, real 15) |
| Haller delta | +5.2 goals (expected 5.8, real 11) |
| Nkunku delta | +6.4 goals (expected 0.6, real 7) |
Technical architecture & ownership
- Data engineering: Five-stage pipeline orchestrated as Node scripts. Idempotent by design — every script drops and rebuilds its target tables, so the whole pipeline runs in ~15 seconds from raw CSVs to populated predictions table.
- Name matching: UCL calls him "Benzema"; FIFA calls him "Karim Benzema" or "K. Benzema". Clubs disagree too ("Bayern" vs "FC Bayern München"). A custom fuzzy-match layer normalizes both sides, indexes FIFA players by every meaningful club token crossed with last name, and scores candidates by Levenshtein similarity — 88% auto-match rate across the 750 UCL players.
- Model lifecycle: Train + predict collapsed into a single script. Since TF.js-in-Node doesn't need native file handles for the model weights in this use case, skipping the save-then-load round trip simplified deployment without sacrificing reproducibility (deterministic seeded shuffle).
- Backend: Express on port 3001,
better-sqlite3for synchronous reads, service layer that isolates SQL from routing. Three REST endpoints do everything the frontend needs. - Frontend: React 18 + Vite 6, zero UI framework — handwritten components with CSS custom properties for theming. Dev proxy forwards
/apito the Express server so there's no CORS dance or environment flag juggling.
Stack
- ML: TensorFlow.js (pure-JS
@tensorflow/tfjs, runs in any Node without native bindings) - Data: SQLite via
better-sqlite3, xlsx parsing, CSV streaming,fastest-levenshteinfor fuzzy matching - Backend: Express 4, Node 22+,
cors, module-type ESM - Frontend: React 18, Vite 6, handwritten CSS + design tokens
- i18n: Flat translations object, 3 languages (PT-BR, EN-US, ES)
- Dev UX:
concurrently+nodemonorchestrate Vite and Express in one npm command
System operations (CLI)
Key pipeline commands — each script is idempotent, so they can be rerun in any order to rebuild downstream state:
npm run ingest:fifa— parse the FIFA 22 xlsx into SQLite (19,239 rows)npm run ingest:ucl— merge 8 UCL CSVs into one unified player tablenpm run match— fuzzy-join FIFA × UCL with Levenshtein scoringnpm run train— train the MLP, generate predictions, persist deltasnpm run pipeline— run all four in sequencenpm run dev:all— Vite (5173) + Express (3001) side by side
Engineering highlights
- End-to-end ML in JavaScript. No Python handoff. The same TensorFlow.js package that trains the model in Node during the pipeline could serve inference in the browser — a natural v2 extension. The model, its training code, the API that serves its outputs, and the UI that renders them all live in the same monorepo.
- The position-filter insight. The most consequential decision in the pipeline wasn't a hyperparameter — it was realizing that the MSE loss was collapsing predictions toward the mean of a defender-heavy cohort. Filtering the training set to only offensive positions moved Benzema's expected goals from 4.4 to 9.2 without touching a single line of model code. Classic case of the input distribution mattering more than the architecture.
- Honest uncertainty surfaced in the UI. A dedicated methodology modal documents the dataset, training setup, validation MAE, and known limitations (small cohort, mid-season transfers, MSE bias toward the mean). Portfolio-grade ML work is explicit about what the model can't do — not just what it can.
- Designer-led then engineered. The first version of the UI came from a Claude Artifacts-generated prototype, which I refactored into a proper Vite + React module structure: scoped component folders, a custom hook layer for API consumption, an i18n system, and themed primitives. The design stayed; the scaffolding became production-shaped.